
解读JVM级别本地缓存Caffeine青出于蓝的要诀 —— 缘何会更强、如何去上手
继Guava Cache之后,我们再来聊一下各方面表现都更佳的Caffeine,看一下其具体使用方式、核心的优化改进点,窥探其青出于蓝的秘密所在。

大家好,又见面了。
本文是笔者作为掘金技术社区签约作者的身份输出的缓存专栏系列内容,将会通过系列专题,讲清楚缓存的方方面面。如果感兴趣,欢迎关注以获取后续更新。
在前面的几篇文章中,我们一起聊了下本地缓存的动手实现、本地缓存相关的规范等,也聊了下Google的Guava Cache的相关原理与使用方式。比较心急的小伙伴已经坐不住了,提到本地缓存,怎么能不提一下“地上最强”的Caffeine Cache呢?
能被小伙伴称之为“地上最强”,可见Caffeine的魅力之大!的确,提到JAVA中的本地缓存框架,Caffeine是怎么也没法轻视的重磅嘉宾。前面几篇文章中,我们一起探索了JVM级别的优秀缓存框架Guava Cache,而相比之下,Caffeine可谓是站在巨人肩膀上,在很多方面做了深度的优化与改良,可以说在性能表现与命中率上全方位的碾压Guava Cache,表现堪称卓越。
下面就让我们一起来解读下Caffeine Cache的设计实现改进点原理,揭秘Caffeine Cache青出于蓝的秘密所在,并看下如何在项目中快速的上手使用。

巨人肩膀上的产物
先来回忆下之前创建一个Guava cache对象时的代码逻辑:
public LoadingCache<String, User> createUserCache() {
return CacheBuilder.newBuilder()
.initialCapacity(1000)
.maximumSize(10000L)
.expireAfterWrite(30L, TimeUnit.MINUTES)
.concurrencyLevel(8)
.recordStats()
.build((CacheLoader<String, User>) key -> userDao.getUser(key));
}而使用Caffeine来创建Cache对象的时候,我们可以这么做:
public LoadingCache<String, User> createUserCache() {
return Caffeine.newBuilder()
.initialCapacity(1000)
.maximumSize(10000L)
.expireAfterWrite(30L, TimeUnit.MINUTES)
//.concurrencyLevel(8)
.recordStats()
.build(key -> userDao.getUser(key));
}可以发现,两者的使用思路与方法定义非常相近,对于使用过Guava Cache的小伙伴而言,几乎可以无门槛的直接上手使用。当然,两者也还是有点差异的,比如Caffeine创建对象时不支持使用concurrencyLevel来指定并发量(因为改进了并发控制机制),这些我们在下面章节中具体介绍。
相较于Guava Cache,Caffeine在整体设计理念、实现策略以及接口定义等方面都基本继承了前辈的优秀特性。作为新时代背景下的后来者,Caffeine也做了很多细节层面的优化,比如:
基础数据结构层面优化
借助JAVA8对ConcurrentHashMap底层由链表切换为红黑树、以及废弃分段锁逻辑的优化,提升了Hash冲突时的查询效率以及并发场景下的处理性能。数据驱逐(淘汰)策略的优化
通过使用改良后的W-TinyLFU算法,提供了更佳的热点数据留存效果,提供了近乎完美的热点数据命中率,以及更低消耗的过程维护异步并行能力的全面支持
完美适配JAVA8之后的并行编程场景,可以提供更为优雅的并行编码体验与并发效率。
通过各种措施的改良,成就了Caffeine在功能与性能方面不俗的表现。
Caffeine与Guava —— 是传承而非竞争
很多人都知道Caffeine在各方面的表现都由于Guava Cache, 甚至对比之下有些小伙伴觉得Guava Cache简直一无是处。但不可否认的是,在曾经的一段时光里,Guava Cache提供了尽可能高效且轻量级的并发本地缓存工具框架。技术总是在不断的更新与迭代的,纵使优秀如Guava Cache这般,终究是难逃沦为时代眼泪的结局。
纵观Caffeine,其原本就是基于Guava cache基础上孵化而来的改良版本,众多的特性与设计思路都完全沿用了Guava Cache相同的逻辑,且提供的接口与使用风格也与Guava Cache无异。所以,从这个层面而言,本人更愿意将Caffeine看作是Guava Cache的一种优秀基因的传承与发扬光大,而非是竞争与打压关系。
那么Caffeine能够青出于蓝的秘诀在哪呢?下面总结了其最关键的3大要点,一起看下。
贯穿始终的异步策略
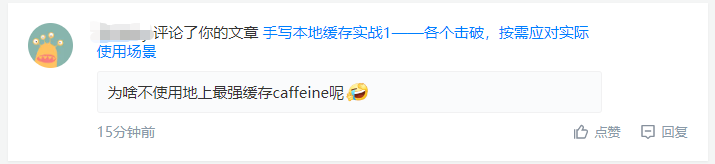
Caffeine在请求上的处理流程做了很多的优化,效果比较显著的当属数据淘汰处理执行策略的改进。之前在Guava Cache的介绍中,有提过Guava Cache的策略是在请求的时候同时去执行对应的清理操作,也就是读请求中混杂着写操作,虽然Guava Cache做了一系列的策略来减少其触发的概率,但一旦触发总归是会对读取操作的性能有一定的影响。
Caffeine则采用了异步处理的策略,get请求中虽然也会触发淘汰数据的清理操作,但是将清理任务添加到了独立的线程池中进行异步的不会阻塞 get 请求的执行与返回,这样大大缩短了get请求的执行时长,提升了响应性能。
除了对自身的异步处理优化,Caffeine还提供了全套的Async异步处理机制,可以支持业务在异步并行流水线式处理场景中使用以获得更加丝滑的体验。
Caffeine完美的支持了在异步场景下的流水线处理使用场景,回源操作也支持异步的方式来完成。CompletableFuture并行流水线能力,是JAVA8在异步编程领域的一个重大改进。可以将一系列耗时且无依赖的操作改为并行同步处理,并等待各自处理结果完成后继续进行后续环节的处理,由此来降低阻塞等待时间,进而达到降低请求链路时长的效果。
比如下面这段异步场景使用Caffeine并行处理的代码:
public static void main(String[] args) throws Exception {
AsyncLoadingCache<String, String> asyncLoadingCache = buildAsyncLoadingCache();
// 写入缓存记录(value值为异步获取)
asyncLoadingCache.put("key1", CompletableFuture.supplyAsync(() -> "value1"));
// 异步方式获取缓存值
CompletableFuture<String> completableFuture = asyncLoadingCache.get("key1");
String value = completableFuture.join();
System.out.println(value);
}
ConcurrentHashMap优化特性
作为使用JAVA8新特性进行构建的Caffeine,充分享受了JAVA8语言层面优化改进所带来的性能上的增益。我们知道ConcurrentHashMap是JDK原生提供的一个线程安全的HashMap容器类型,而Caffeine底层也是基于ConcurrentHashMap进行构建与数据存储的。
在JAVA7以及更早的版本中,ConcurrentHashMap采用的是分段锁的策略来实现线程安全的(前面文章中我们讲过Guava Cache采用的也是分段锁的策略),分段锁虽然在一定程度上可以降低锁竞争的冲突,但是在一些极高并发场景下,或者并发请求分布较为集中的时候,仍然会出现较大概率的阻塞等待情况。此外,这些版本中ConcurrentHashMap底层采用的是数组+链表的存储形式,这种情况在Hash冲突较为明显的情况下,需要频繁的遍历链表操作,也会影响整体的处理性能。
JAVA8中对ConcurrentHashMap的实现策略进行了较大调整,大幅提升了其在的并发场景的性能表现。主要可以分为2个方面的优化。
- 数组+链表结构自动升级为
数组+红黑树
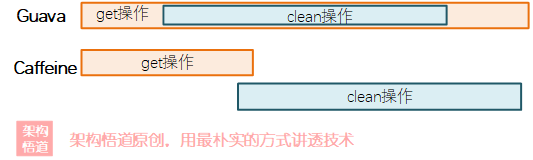
默认情况下,ConcurrentHashMap的底层结构是数组+链表的形式,元素存储的时候会先计算下key对应的Hash值来将其划分到对应的数组对应的链表中,而当链表中的元素个数超过8个的时候,链表会自动转换为红黑树结构。如下所示:
在遍历查询方面,红黑树有着比链表要更加卓越的性能表现。
- 分段锁升级为
synchronized+CAS锁
分段锁的核心思想就是缩小锁的范围,进而降低锁竞争的概率。当数据量特别大的时候,其实每个锁涵盖的数据范围依旧会很大,如果并发请求量特别大的时候,依旧会出现很多线程抢夺同一把分段锁的情况。
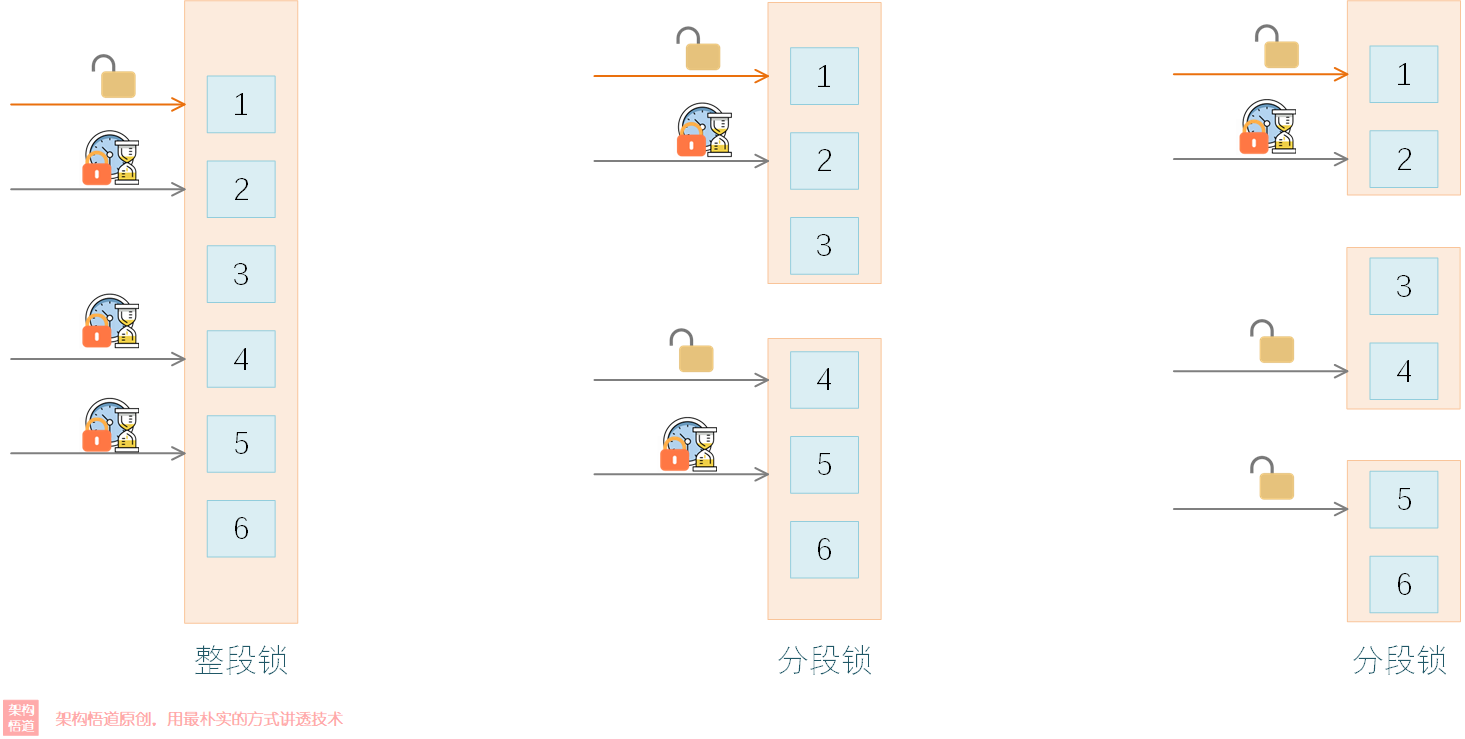
在JAVA8中,ConcurrentHashMap 废弃分段锁的概念,改为了synchronized+CAS的策略,借助CAS的乐观锁策略,大大提升了读多写少场景下的并发能力。
得益于JAVA8对ConcurrentHashMap的优化,使得Caffeine在多线程并发场景下的表现非常的出色。
淘汰算法W-LFU的加持
常规的缓存淘汰算法一般采用FIFO、LRU或者LFU,但是这些算法在实际缓存场景中都会存在一些弊端:
| 算法 | 弊端说明 |
|---|---|
| FIFO | 先进先出策略,属于一种最为简单与原始的策略。如果缓存使用频率较高,会导致缓存数据始终在不停的进进出出,影响性能,且命中率表现也一般。 |
| LRU | 最近最久未使用策略,保留最近被访问到的数据,而淘汰最久没有被访问的数据。如果遇到偶尔的批量刷数据情况,很容易将其他缓存内容都挤出内存,带来缓存击穿的风险。 |
| LFU | 最近少频率策略,这种根据访问次数进行淘汰,相比而言内存中存储的热点数据命中率会更高些,缺点就是需要维护独立字段用来记录每个元素的访问次数,占用内存空间。 |
为了保证命中率,一般缓存框架都会选择使用LRU或者LFU策略,很少会有使用FIFO策略进行数据淘汰的。Caffeine缓存的LFU采用了Count-Min Sketch频率统计算法(参见下图示意,图片来源:点此查看),由于该LFU的计数器只有4bit大小,所以称为TinyLFU。在TinyLFU算法基础上引入一个基于LRU的Window Cache,这个新的算法叫就叫做W-TinyLFU。
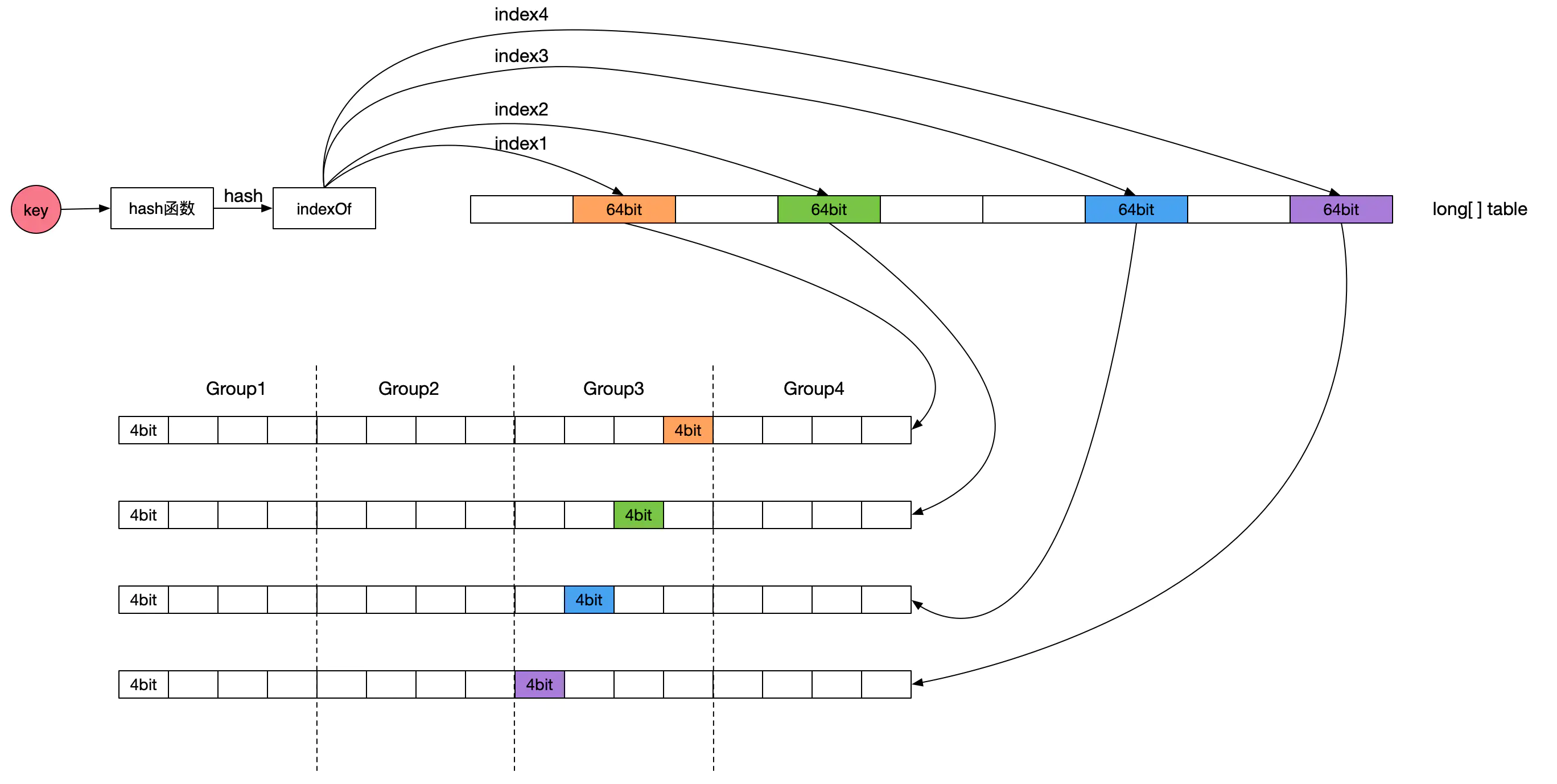
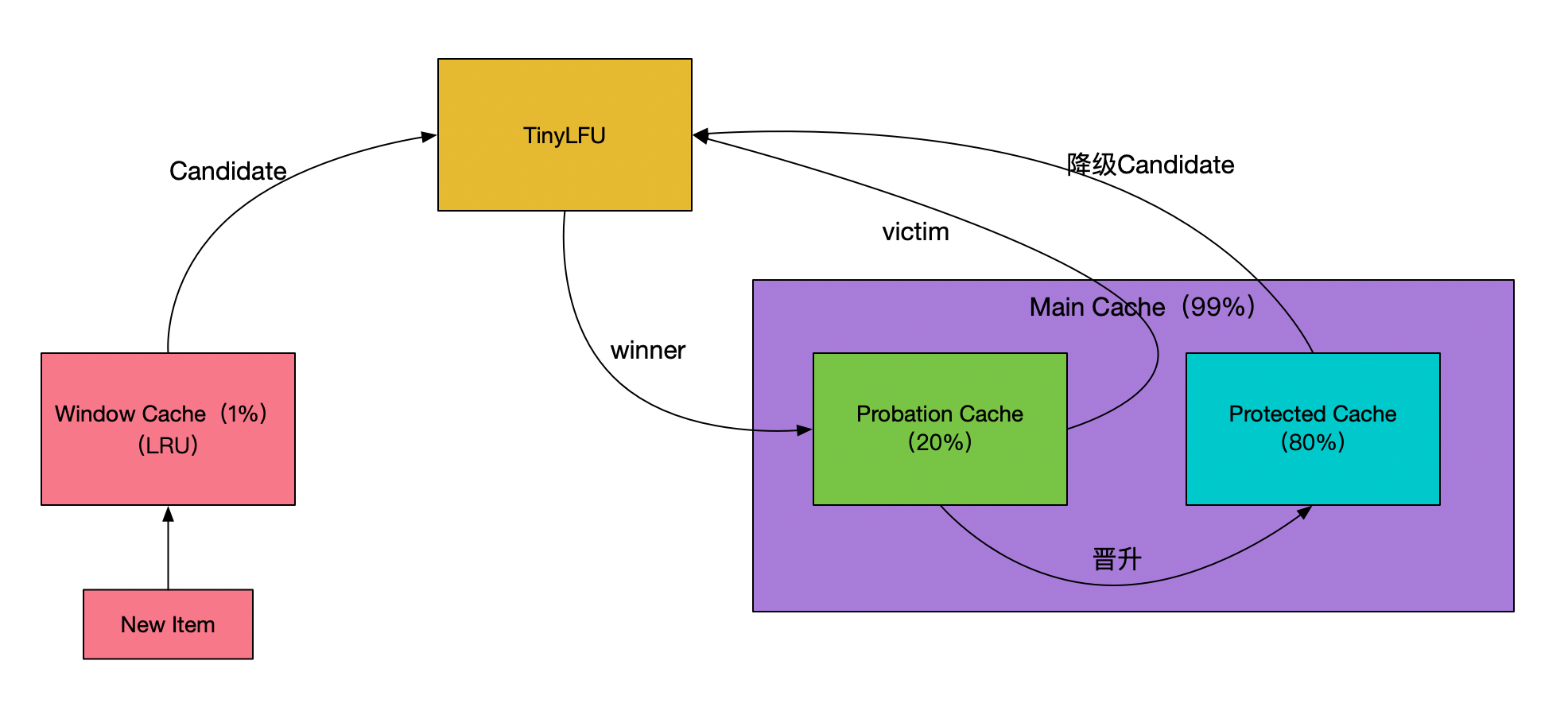
W-TinyLFU算法有效的解决了LRU以及LFU存在的弊端,为Caffeine提供了大部分场景下近乎完美的命中率表现。
关于W-TinyLFU的具体说明,有兴趣的话可以点此了解。
如何选择
在Caffeine与Guava Cache之间如何选择?其实Spring已经给大家做了示范,从Spring5开始,其内置的本地缓存框架由Guava Cache切换到了Caffeine。应用到项目中的缓存选型,可以结合项目实际从多个方面进行抉择。
全新项目,闭眼选Caffeine
Java8也已经被广泛的使用多年,现在的新项目基本上都是JAVA8或以上的版本了。如果有新的项目需要做本地缓存选型,闭眼选择Caffeine就可以,错不了。历史低版本JAVA项目
由于Caffeine对JAVA版本有依赖要求,对于一些历史项目的维护而言,如果项目的JDK版本过低则无法使用Caffeine,这种情况下Guava Cache依旧是一个不错的选择。当然,也可以下定决心将项目的JDK版本升级到JDK1.8+版本,然后使用Caffeine来获得更好的性能体验 —— 但是对于一个历史项目而言,升级基础JDK版本带来的影响可能会比较大,需要提前评估好。有同时使用Guava其它能力
如果你的项目里面已经有引入并使用了Guava提供的相关功能,这种情况下为了避免太多外部组件的引入,也可以直接使用Guava提供的Cache组件能力,毕竟Guava Cache的表现并不算差,应付常规场景的本都缓存诉求完全足够。当然,为了追求更加极致的性能表现,另外引入并使用Caffeine也完全没有问题。
Caffeine使用
依赖引入
使用Caffeine,首先需要引入对应的库文件。如果是Maven项目,则可以在pom.xml中添加依赖声明来完成引入。
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>3.1.1</version>
</dependency>注意,如果你的本地JDK版本比较低,引入上述较新版本的时候可能会编译报错:

遇到这种情况,可以考虑升级本地JDK版本(实际项目中升级可能有难度),或者将Caffeine版本降低一些,比如使用2.9.3版本。具体的版本列表,可以点击此处进行查询。
这样便大功告成啦。
容器创建
和之前我们聊过的Guava Cache创建缓存对象的操作相似,我们可以通过构造器来方便的创建出一个Caffeine对象。
Cache<Integer, String> cache = Caffeine.newBuilder().build();除了上述这种方式,Caffeine还支持使用不同的构造器方法,构建不同类型的Caffeine对象。对各种构造器方法梳理如下:
| 方法 | 含义说明 |
|---|---|
| build() | 构建一个手动回源的Cache对象 |
| build(CacheLoader) | 构建一个支持使用给定CacheLoader对象进行自动回源操作的LoadingCache对象 |
| buildAsync() | 构建一个支持异步操作的异步缓存对象 |
| buildAsync(CacheLoader) | 使用给定的CacheLoader对象构建一个支持异步操作的缓存对象 |
| buildAsync(AsyncCacheLoader) | 与buildAsync(CacheLoader)相似,区别点仅在于传入的参数类型不一样。 |
为了便于异步场景中处理,可以通过buildAsync()构建一个手动回源数据加载的缓存对象:
public static void main(String[] args) {
AsyncCache<String, User> asyncCache = Caffeine.newBuilder()
.buildAsync();
User user = asyncCache.get("123", s -> {
System.out.println("异步callable thread:" + Thread.currentThread().getId());
return userDao.getUser(s);
}).join();
}当然,为了支持异步场景中的自动异步回源,我们可以通过buildAsync(CacheLoader)或者buildAsync(AsyncCacheLoader)来实现:
public static void main(String[] args) throws Exception{
AsyncLoadingCache<String, User> asyncLoadingCache =
Caffeine.newBuilder().maximumSize(1000L).buildAsync(key -> userDao.getUser(key));
User user = asyncLoadingCache.get("123").join();
}在创建缓存对象的同时,可以指定此缓存对象的一些处理策略,比如容量限制、比如过期策略等等。作为以替换Guava Cache为己任的后继者,Caffeine在缓存容器对象创建时的相关构建API也沿用了与Guava Cache相同的定义,常见的方法及其含义梳理如下:
| 方法 | 含义说明 |
|---|---|
| initialCapacity | 待创建的缓存容器的初始容量大小(记录条数) |
| maximumSize | 指定此缓存容器的最大容量(最大缓存记录条数) |
| maximumWeight | 指定此缓存容器的最大容量(最大比重值),需结合weighter方可体现出效果 |
| expireAfterWrite | 设定过期策略,按照数据写入时间进行计算 |
| expireAfterAccess | 设定过期策略,按照数据最后访问时间来计算 |
| expireAfter | 基于个性化定制的逻辑来实现过期处理(可以定制基于新增、读取、更新等场景的过期策略,甚至支持为不同记录指定不同过期时间) |
| weighter | 入参为一个函数式接口,用于指定每条存入的缓存数据的权重占比情况。这个需要与maximumWeight结合使用 |
| refreshAfterWrite | 缓存写入到缓存之后 |
| recordStats | 设定开启此容器的数据加载与缓存命中情况统计 |
综合上述方法,我们可以创建出更加符合自己业务场景的缓存对象。
public static void main(String[] args) {
AsyncLoadingCache<String, User> asyncLoadingCache = CaffeinenewBuilder()
.initialCapacity(1000) // 指定初始容量
.maximumSize(10000L) // 指定最大容量
.expireAfterWrite(30L, TimeUnit.MINUTES) // 指定写入30分钟后过期
.refreshAfterWrite(1L, TimeUnit.MINUTES) // 指定每隔1分钟刷新下数据内容
.removalListener((key, value, cause) ->
System.out.println(key + "移除,原因:" + cause)) // 监听记录移除事件
.recordStats() // 开启缓存操作数据统计
.buildAsync(key -> userDao.getUser(key)); // 构建异步CacheLoader加载类型的缓存对象
}
业务使用
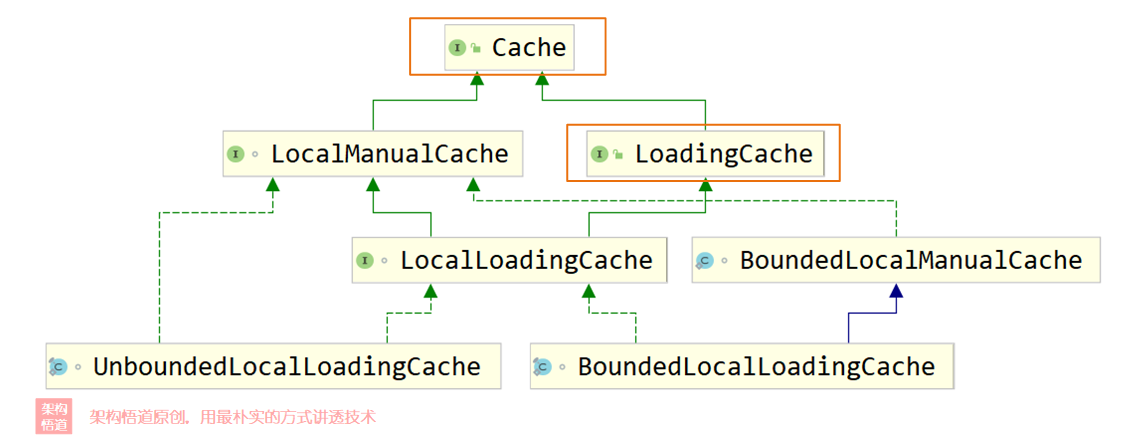
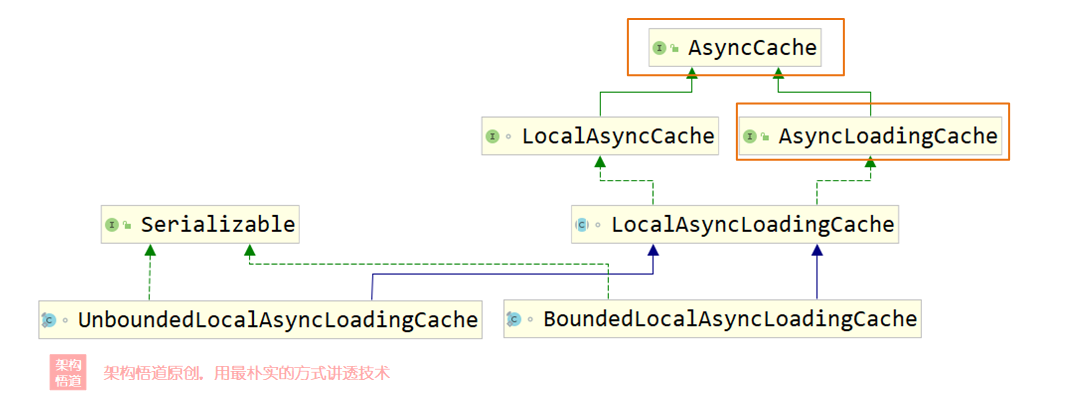
在上一章节创建缓存对象的时候,Caffeine支持创建出同步缓存与异步缓存,也即Cache与AsyncCache两种不同类型。而如果指定了CacheLoader的时候,又可以细分出LoadingCache子类型与AsyncLoadingCache子类型。对于常规业务使用而言,知道这四种类型的缓存类型基本就可以满足大部分场景的正常使用了。但是Caffeine的整体缓存类型其实是细分成了很多不同的具体类型的,从下面的UML图上可以看出一二。
- 同步缓存
- 异步缓存
业务层面对缓存的使用,无外乎往缓存里面写入数据、从缓存里面读取数据。不管是同步还是异步,常见的用于操作缓存的方法梳理如下:
| 方法 | 含义说明 |
|---|---|
| get | 根据key获取指定的缓存值,如果没有则执行回源操作获取 |
| getAll | 根据给定的key列表批量获取对应的缓存值,返回一个map格式的结果,没有命中缓存的部分会执行回源操作获取 |
| getIfPresent | 不执行回源操作,直接从缓存中尝试获取key对应的缓存值 |
| getAllPresent | 不执行回源操作,直接从缓存中尝试获取给定的key列表对应的值,返回查询到的map格式结果, 异步场景不支持此方法 |
| put | 向缓存中写入指定的key与value记录 |
| putAll | 批量向缓存中写入指定的key-value记录集,异步场景不支持此方法 |
| asMap | 将缓存中的数据转换为map格式返回 |
针对同步缓存,业务代码中操作使用举例如下:
public static void main(String[] args) throws Exception {
LoadingCache<String, String> loadingCache = buildLoadingCache();
loadingCache.put("key1", "value1");
String value = loadingCache.get("key1");
System.out.println(value);
}同样地,异步缓存的时候,业务代码中操作示意如下:
public static void main(String[] args) throws Exception {
AsyncLoadingCache<String, String> asyncLoadingCache = buildAsyncLoadingCache();
// 写入缓存记录(value值为异步获取)
asyncLoadingCache.put("key1", CompletableFuture.supplyAsync(() -> "value1"));
// 异步方式获取缓存值
CompletableFuture<String> completableFuture = asyncLoadingCache.get("key1");
String value = completableFuture.join();
System.out.println(value);
}小结回顾
好啦,关于Caffeine Cache的具体使用方式、核心的优化改进点相关的内容,以及与Guava Cache的比较,就介绍到这里了。不知道小伙伴们是否对Caffeine Cache有了全新的认识了呢?而关于Caffeine Cache与Guava Cache的差别,你是否有自己的一些想法与见解呢?欢迎评论区一起交流下,期待和各位小伙伴们一起切磋、共同成长。
下一篇文章中,我们将深入讲解下Caffeine同步、异步回源操作的各种不同实现,以及对应的实现与底层设计逻辑。如有兴趣,欢迎关注后续更新。
📣 补充说明1 :
本文属于《深入理解缓存原理与实战设计》系列专栏的内容之一。该专栏围绕缓存这个宏大命题进行展开阐述,全方位、系统性地深度剖析各种缓存实现策略与原理、以及缓存的各种用法、各种问题应对策略,并一起探讨下缓存设计的哲学。
如果有兴趣,也欢迎关注此专栏。
📣 补充说明2 :
- 关于本文中涉及的演示代码的完整示例,我已经整理并提交到github中,如果您有需要,可以自取:https://github.com/veezean/JavaBasicSkills
我是悟道,聊技术、又不仅仅聊技术~
如果觉得有用,请点赞 + 关注让我感受到您的支持。也可以关注下我的公众号【架构悟道】,获取更及时的更新。
期待与你一起探讨,一起成长为更好的自己。


 码字不易,感谢鼓励
码字不易,感谢鼓励
