
Spring Data JPA系列5:让IDEA自动帮你写JPA实体定义代码

大家好,又见面了。
这是本系列的最后一篇文档啦,先来回顾下前面几篇:
在第1篇《Spring Data JPA系列1:JDBC、ORM、JPA、Spring Data JPA,傻傻分不清楚?给你个选择SpringDataJPA的理由!》中,我们对JPA的整体概念有了全面的了解。
在第2篇《Spring Data JPA系列2:快速在SpringBoot项目中熟练使用JPA》中也知晓了SpringBoot项目快速集成SpringData JPA以及快速上手使用JPA来进行基本的项目开发的技能。
在第3篇《Spring Data JPA系列3:JPA项目中核心场景与进阶用法介绍》进一步的聊一下项目中使用JPA的一些高阶复杂场景的实践指导,覆盖了主要核心的JPA使用场景。
在第4篇《Spring Data JPA系列4:Spring声明式事务处理与多数据源支持》我们对数据库事务处理方式以及可能存在的问题等进行了全面的探讨。
通过前面的系列文档,我们一起对SpringData JPA从浅入深的进行了全方位的探讨。正所谓“工欲善其事、必先利其器”,面对一个优秀的框架,如果再结合一些外部的工具,其实可以让我们的开发效率与程序员开发过程的体验更上一层楼的。
本篇内容,我们就一起来聊一聊这方面。
借助IDEA提升效率
IDEA中直接连接数据源
项目开发的时候,经常需要一边写代码一边看下数据库表数据或者字段,需要在IDEA和数据库客户端之间来回切换,很麻烦。其实,IDEA中可以直接连接数据库,直接在IDEA中查看和执行数据库操作,更加的方便快捷。
- 打开View -> Tool Windows -> Database窗口
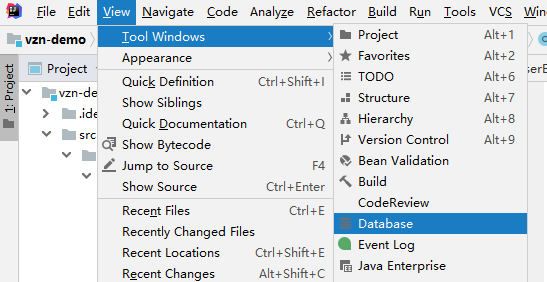
- 添加数据库连接,点击+号 -> Data Source -> MySQL,如果需要连接其他类型数据库,按需选择
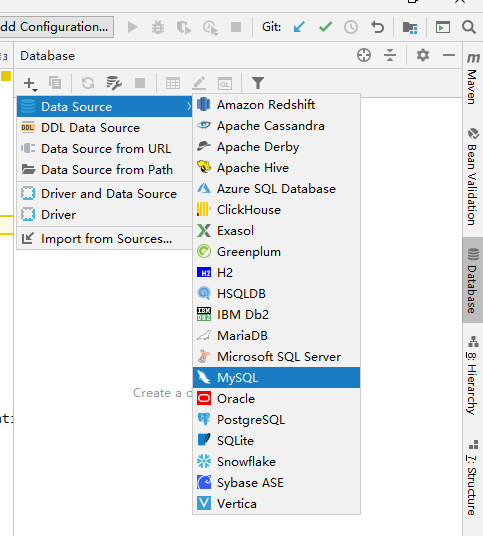
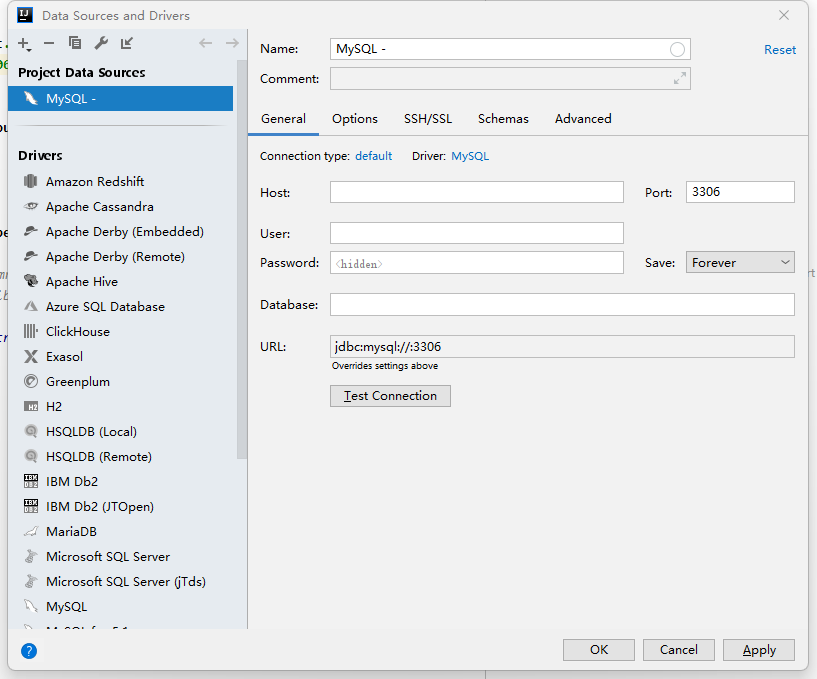
- 填写Host、User、Password、Database等连接信息,填好后点击OK
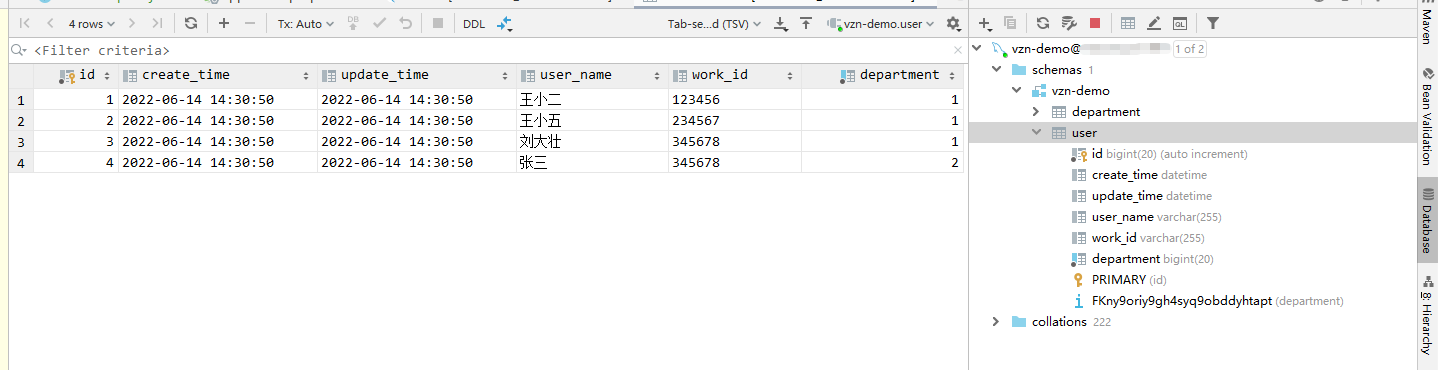
- 连接完成,可以查看DB中数据,双击表名,可以查看表中数据内容
- 点击打开Console窗口,可以输入SQL语句并执行
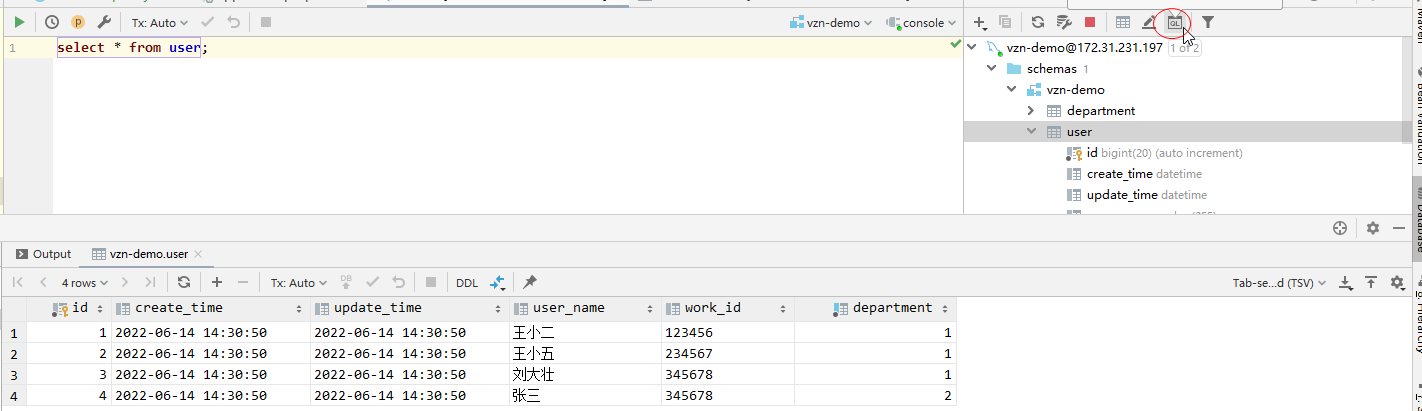
OK, Enjoy it…
IDEA自动生成实体对象
数据表定义好了,手动逐个写对应的映射实体Entity,还是很繁琐?教你让IDEA自动给你生成Entity实体类!
- 打开IDEA,点击File -> Project Structure菜单
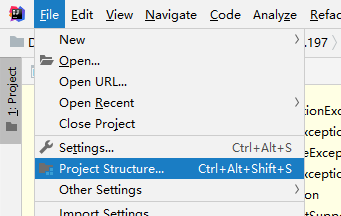
- 打开的窗口中,点击Modules,点击右侧+号按钮,选择JPA菜单
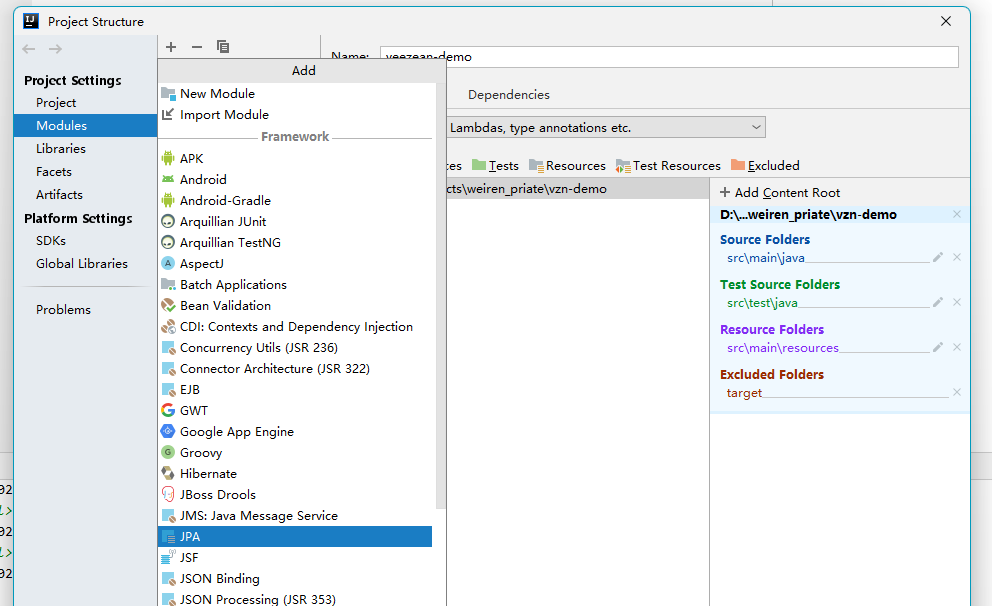
- 选中JPA选项,切换下面Default JPA provider为Hibernate,点击OK
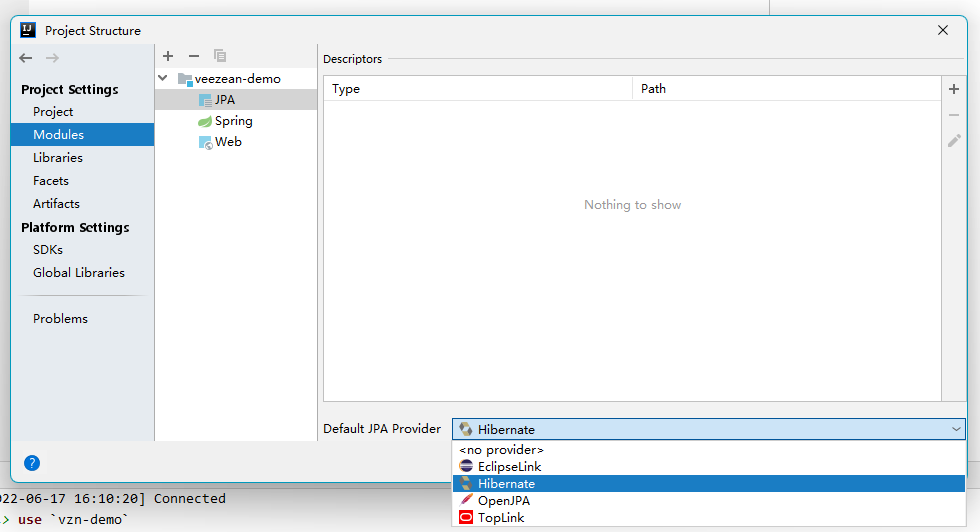
- IDEA窗口中多了个Persistence窗口,点击打开
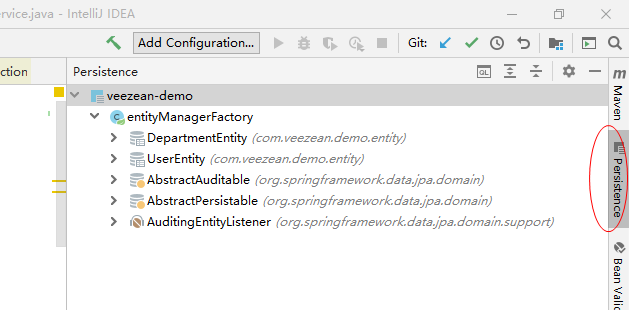
- 在Persistence窗口中选择项目名称,右键点击Generate Persistence Mapping -> By Database Schema
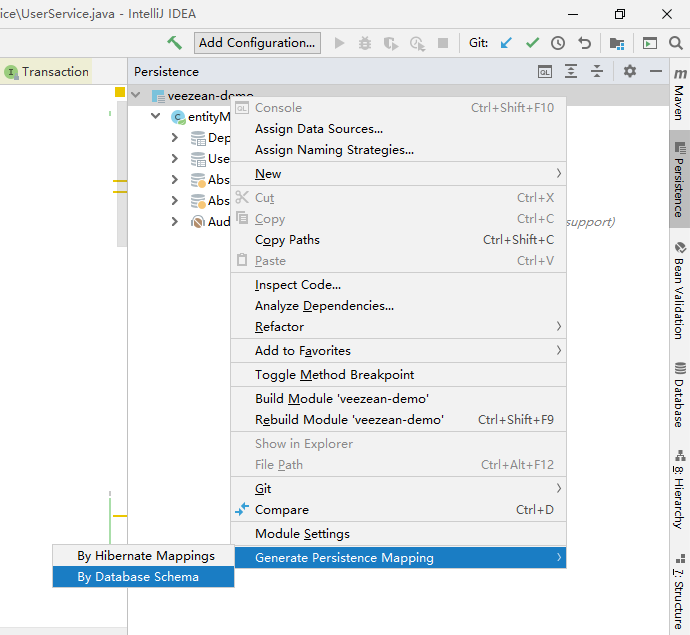
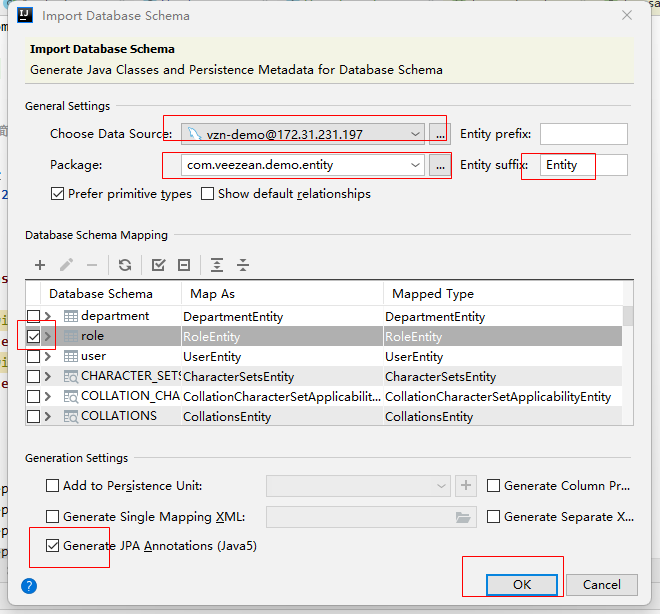
- 弹窗中,选择一个数据源(上一章节中讲解的方式配置IDEA与DB的连接),选择代码生成到的代码目标package位置,设定代码生成类名命名规则(prefix或者suffix),然后勾选需要生成对应代码实体的表,勾选左下角Generate JPA Annotations选项,点击OK
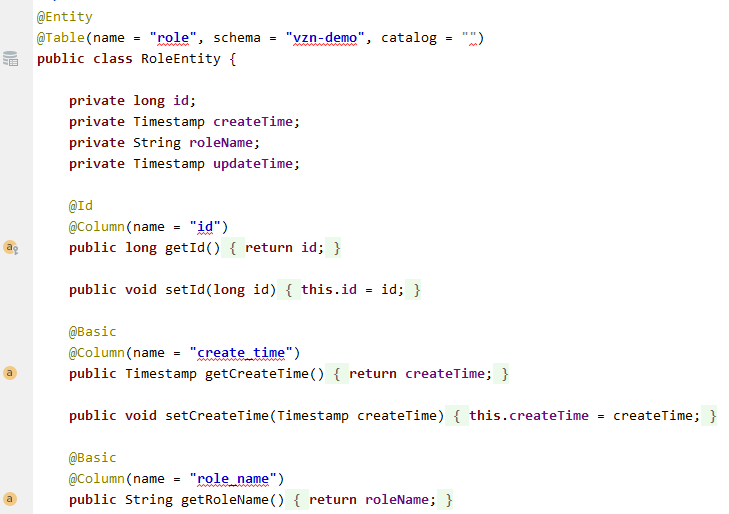
- 等一会儿,对应Entity类就会生成到上一步中指定的位置了。
- 后续再需要生成新的表对应实体类的时候,直接执行5~6两个步骤即可。
后端也想写出完美界面?必须安排!
不知道大家有没有过这种经历:
- 作为一名后端程序员,往往有一个很好的idea,想自己开发个小系统或者小项目,但苦于自己只能写后端服务,没法配上一个美美的web界面。花了点时间学了下Vue或者React等前端脚手架之后,勉强写出来的界面又丑又难用,而且同时维护前后端太耗费精力,最后很多优秀的idea都消失在岁月的洪流中。
- 小型团队,人力有限,没有配齐前后端人员,让后端人员开发蹩脚前端portal,导致整体体验感较差
- …
这里开源项目Erupt就要登场了,可以完美解决上述问题,堪称后端程序员的福音。
为什么在SpringData JPA相关教程中提到这个问题呢?因为Erupt的实现思路与JPA ORM的思路非常相似,对于SpringData JPA做数据处理的项目而言,可以非常简单的几个操作就对接到Erupt上!
详细了解的话,可以去开源项目地址了解下,点此了解
- Erupt的架构图如下:
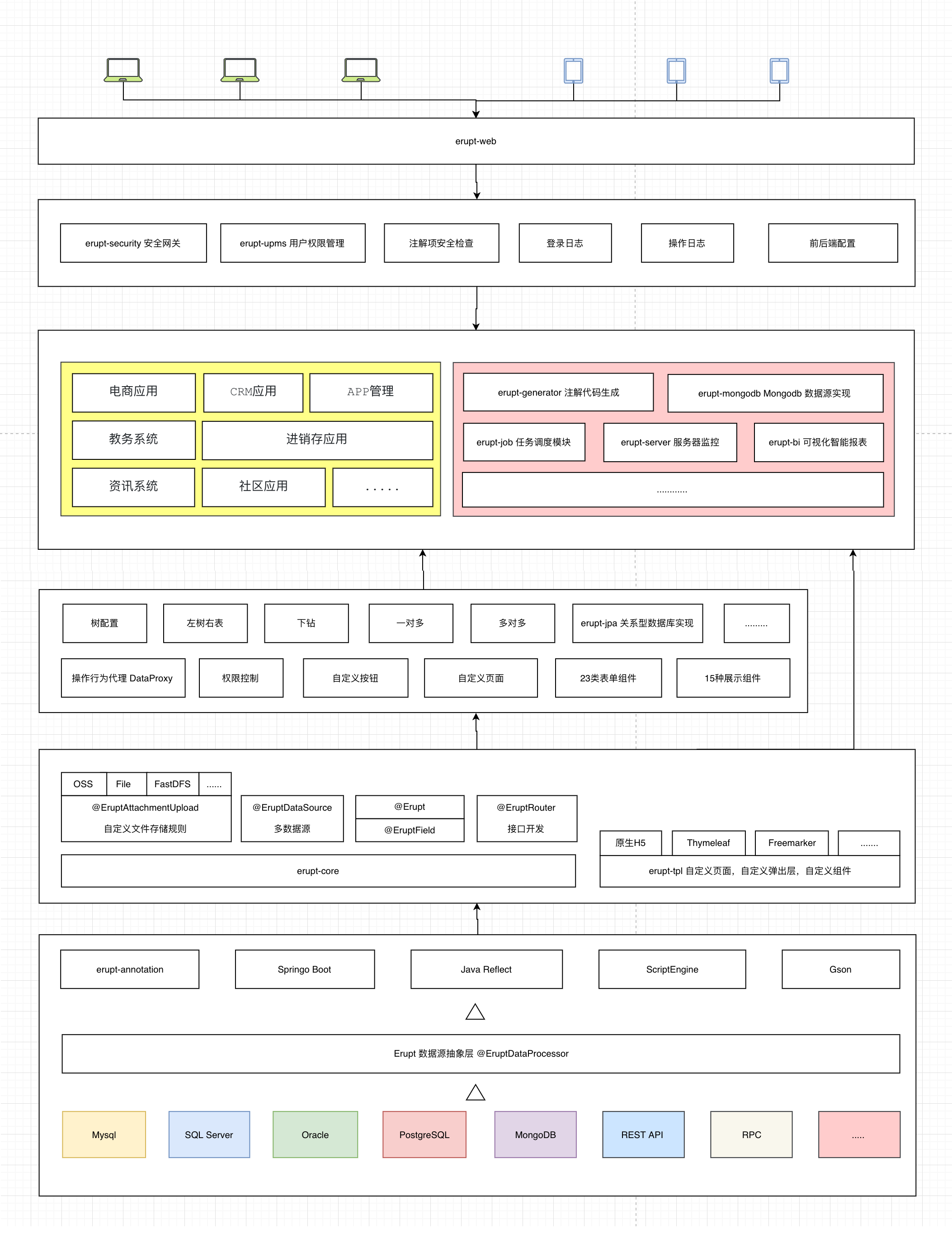
- Erupt界面效果如下:
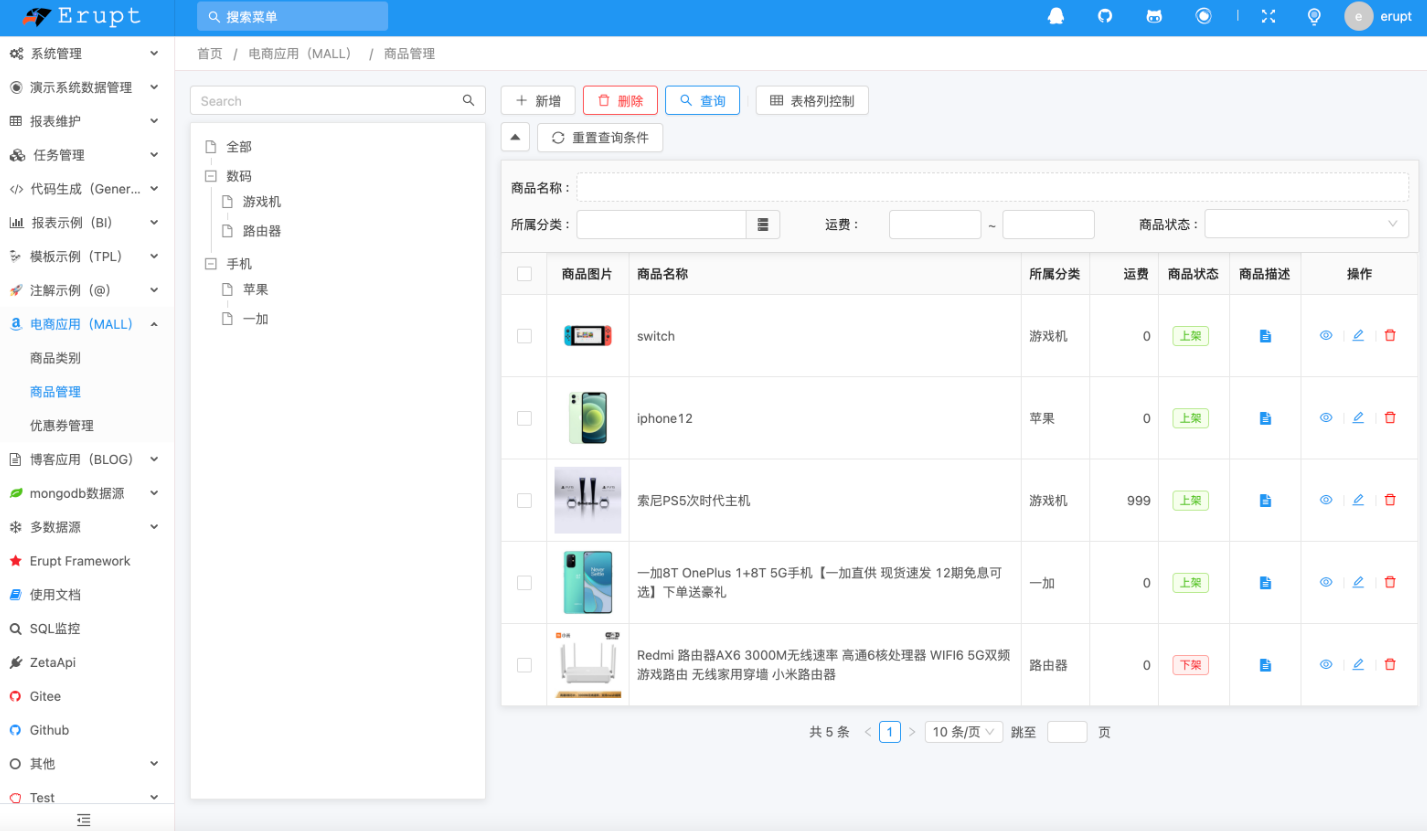
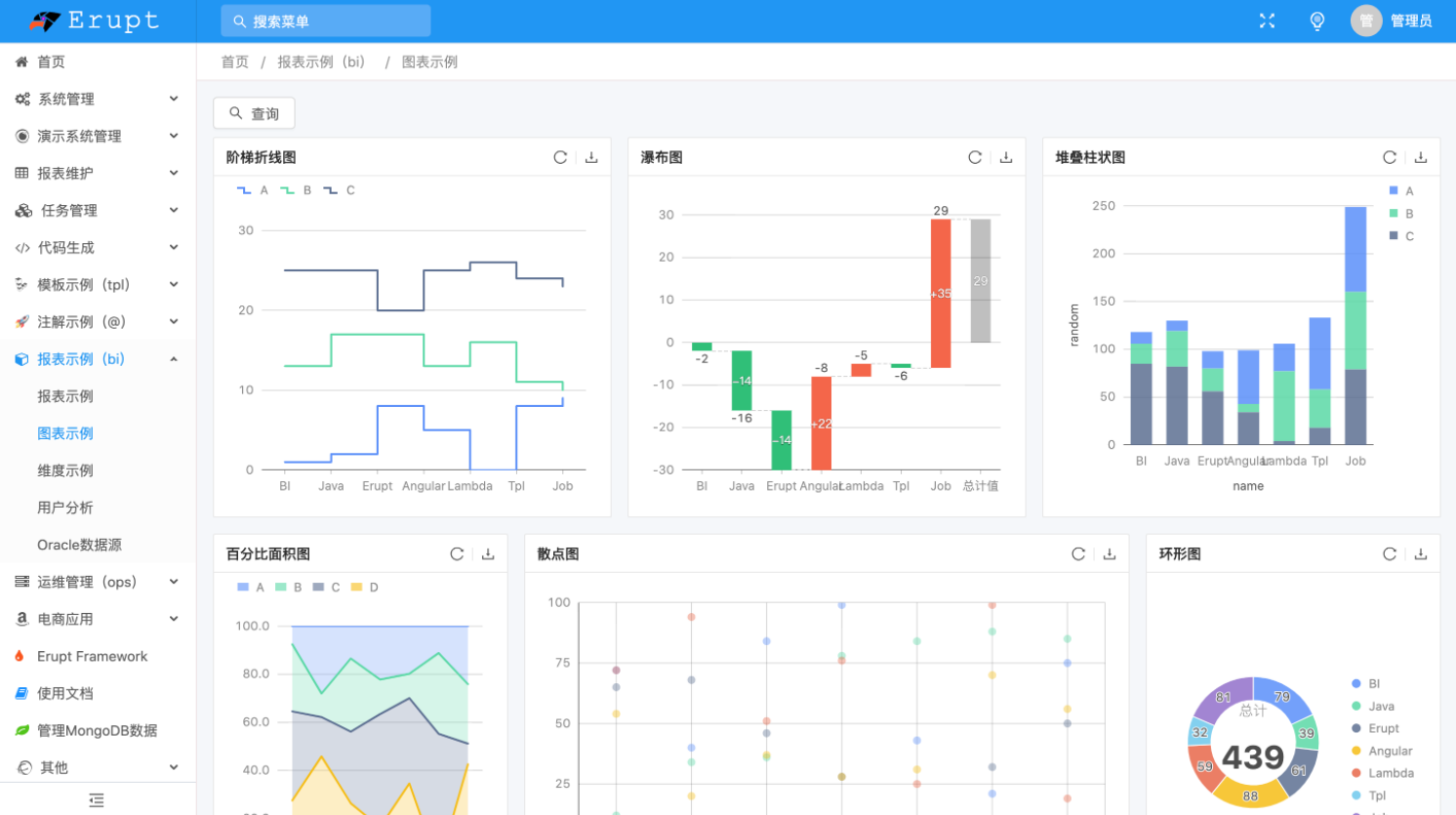
小结
好啦,本篇内容就介绍到这里。
至此,本系列的教程就全部结束啦。通过本系列的几篇文档,为大家由浅入深的对JPA进行了全面的探讨,希望能够让大家对SpringData JPA的学习与使用有一定的帮助。也祝愿大家能够在实际项目中,感受到JPA给我们开发过程带来的便捷。
如果对本文有自己的见解,或者有任何的疑问或建议,都可以留言,我们一起探讨、共同进步。
补充
Spring Data JPA作为Spring Data中对于关系型数据库支持的一种框架技术,属于ORM的一种,通过得当的使用,可以大大简化开发过程中对于数据操作的复杂度。本文档隶属于《
Spring Data JPA用法与技能探究》系列的第5篇。本系列文档规划对Spring Data JPA进行全方位的使用介绍,一共分为5篇文档,如果感兴趣,欢迎关注交流。《Spring Data JPA用法与技能探究》系列涵盖内容:
我是悟道,聊技术、又不仅仅聊技术~
如果觉得有用,请点个关注,也可以关注下我的公众号【架构悟道】,获取更及时的更新。
期待与你一起探讨,一起成长为更好的自己。

 码字不易,感谢鼓励
码字不易,感谢鼓励





