
解读JVM级别本地缓存Caffeine青出于蓝的要诀2 —— 弄清楚Caffeine的同步、异步回源方式
作为一种对外提供黑盒缓存能力的专门组件,Caffeine基于穿透型缓存模式进行构建。本文就深度全面聊一聊关于Caffeine的多种不同的数据回源方式、以及在同步异步场景下的实现与使用。

大家好,又见面了。
本文是笔者作为掘金技术社区签约作者的身份输出的缓存专栏系列内容,将会通过系列专题,讲清楚缓存的方方面面。如果感兴趣,欢迎关注以获取后续更新。
上一篇文章中,我们继Guava Cache之后,又认识了青出于蓝的Caffeine。作为一种对外提供黑盒缓存能力的专门组件,Caffeine基于穿透型缓存模式进行构建。也即对外提供数据查询接口,会优先在缓存中进行查询,若命中缓存则返回结果,未命中则尝试去真正的源端(如:数据库)去获取数据并回填到缓存中,返回给调用方。
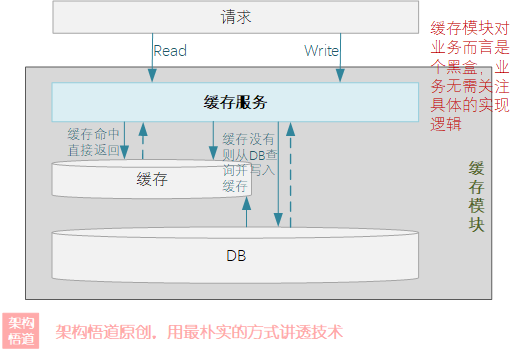
与Guava Cache相似,Caffeine的回源填充主要有两种手段:
Callable方式CacheLoader方式
根据执行调用方式不同,又可以细分为同步阻塞方式与异步非阻塞方式。
本文我们就一起探寻下Caffeine的多种不同的数据回源方式,以及对应的实际使用。

同步方式
同步方式是最常被使用的一种形式。查询缓存、数据回源、数据回填缓存、返回执行结果等一系列操作都是在一个调用线程中同步阻塞完成的。
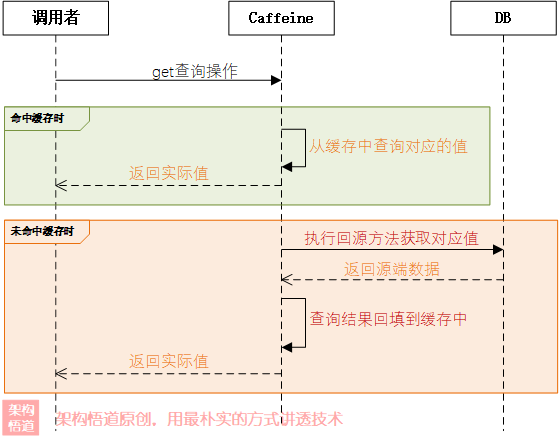
Callable
在每次get请求的时候,传入一个Callable函数式接口具体实现,当没有命中缓存的时候,Caffeine框架会执行给定的Callable实现逻辑,去获取真实的数据并且回填到缓存中,然后返回给调用方。
public static void main(String[] args) {
Cache<String, User> cache = Caffeine.newBuilder().build();
User user = cache.get("123", s -> userDao.getUser(s));
System.out.println(user);
}Callable方式的回源填充,有个明显的优势就是调用方可以根据自己的场景,灵活的给定不同的回源执行逻辑。但是这样也会带来一个问题,就是如果需要获取缓存的地方太多,会导致每个调用的地方都得指定下对应Callable回源方法,调用起来比较麻烦,且对于需要保证回源逻辑统一的场景管控能力不够强势,无法约束所有的调用方使用相同的回源逻辑。
这种时候,便需要CacheLoader登场了。
CacheLoader
在创建缓存对象的时候,可以通在build()方法中传入指定的CacheLoader对象的方式来指定回源时默认使用的回源数据加载器,这样当使用方调用get方法获取不到数据的时候,框架就会自动使用给定的CacheLoader对象执行对应的数据加载逻辑。
比如下面的代码中,便在创建缓存对象时指定了当缓存未命中时通过userDao.getUser()方法去DB中执行数据查询操作:
public LoadingCache<String, User> createUserCache() {
return Caffeine.newBuilder()
.maximumSize(10000L)
.build(key -> userDao.getUser(key));
}相比于Callable方式,CacheLoader更适用于所有回源场景使用的回源策略都固定且统一的情况。对具体业务使用的时候更加的友好,调用get方法也更加简单,只需要传入带查询的key值即可。
上面的示例代码中还有个需要关注的点,即创建缓存对象的时候指定了CacheLoader,最终创建出来的缓存对象是LoadingCache类型,这个类型是Cache的一个子类,扩展提供了无需传入Callable参数的get方法。进一步地,我们打印出对应的详细类名,会发现得到的缓存对象具体类型为:
com.github.benmanes.caffeine.cache.BoundedLocalCache.BoundedLocalLoadingCache当然,如果创建缓存对象的时候没有指定最大容量限制,则创建出来的缓存对象还可能会是下面这个:
com.github.benmanes.caffeine.cache.UnboundedLocalCache.UnboundedLocalManualCache通过UML图,可以清晰的看出其与Cache之间的继承与实现链路情况:
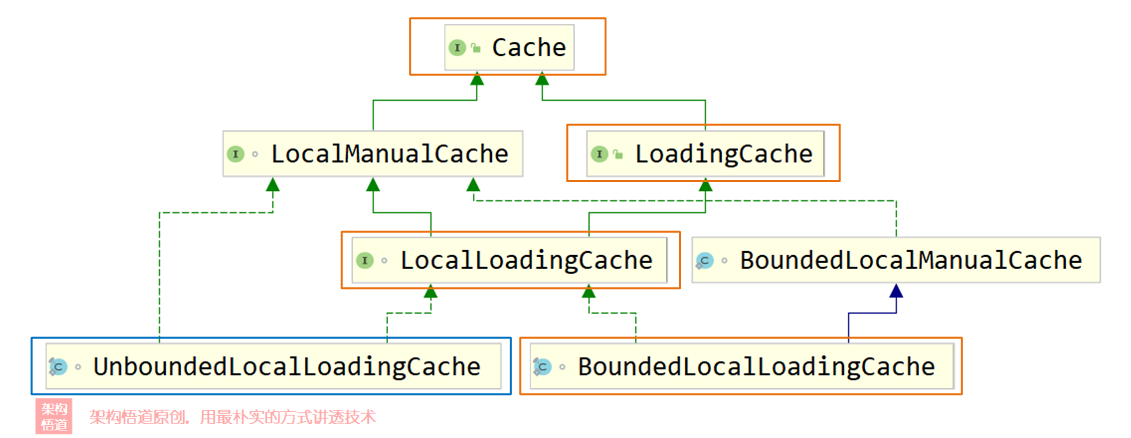
因为LoadingCache是Cache对象的子类,根据JAVA中类继承的特性,LoadingCache也完全具备Cache所有的接口能力。所以,对于大部分场景都需要固定且统一的回源方式,但是某些特殊场景需要自定义回源逻辑的情况,也可以通过组合使用Callable的方式来实现。
比如下面这段代码:
public static void main(String[] args) {
LoadingCache<String, User> cache = Caffeine.newBuilder().build(userId -> userDao.getUser(userId));
// 使用CacheLoader回源
User user = cache.get("123");
System.out.println(user);
// 使用自定义Callable回源
User techUser = cache.get("J234", userId -> {
// 仅J开头的用户ID才会去回源
if (!StringUtils.isEmpty(userId) && userId.startsWith("J")) {
return userDao.getUser(userId);
} else {
return null;
}
});
System.out.println(techUser);
}上述代码中,构造的是一个指定了CacheLoader的LoadingCache缓存类型,这样对于大众场景可以直接使用get方法由CacheLoader提供统一的回源能力,而特殊场景中也可以在get方法中传入需要的定制化回源Callable逻辑。
不回源
在实际的缓存应用场景中,并非是所有的场景都要求缓存没有命中的时候要去执行回源查询。对于一些业务规划上无需执行回源操作的请求,也可以要求Caffeine不要执行回源操作(比如黑名单列表,只要用户在黑名单就禁止操作,不在黑名单则允许继续往后操作,因为大部分请求都不会命中到黑名单中,所以不需要执行回源操作)。为了实现这一点,在查询操作的时候,可以使用Caffeine提供的免回源查询方法来实现。
具体梳理如下:
| 接口 | 功能说明 |
|---|---|
| getIfPresent | 从内存中查询,如果存在则返回对应值,不存在则返回null |
| getAllPresent | 批量从内存中查询,如果存在则返回存在的键值对,不存在的key则不出现在结果集里 |
代码使用演示如下:
public static void main(String[] args) {
LoadingCache<String, User> cache = Caffeine.newBuilder().build(userId -> userDao.getUser(userId));
cache.put("124", new User("124", "张三"));
User userInfo = cache.getIfPresent("123");
System.out.println(userInfo);
Map<String, User> presentUsers =
cache.getAllPresent(Stream.of("123", "124", "125").collect(Collectors.toList()));
System.out.println(presentUsers);
}执行结果如下,可以发现执行的过程中并没有触发自动回源与回填操作:
null
{124=User(userName=张三, userId=124)}
异步方式
CompletableFuture并行流水线能力,是JAVA8在异步编程领域的一个重大改进。可以将一系列耗时且无依赖的操作改为并行同步处理,并等待各自处理结果完成后继续进行后续环节的处理,由此来降低阻塞等待时间,进而达到降低请求链路时长的效果。
很多小伙伴对JAVA8之后的CompletableFuture并行处理能力接触的不是很多,有兴趣的可以移步看下我之前专门介绍JAVA8流水线并行处理能力的介绍《JAVA基于CompletableFuture的流水线并行处理深度实践,满满干货》,相信可以让你对ComparableFututre并行编程有全面的认识与理解。
Caffeine完美的支持了在异步场景下的流水线处理使用场景,回源操作也支持异步的方式来完成。
异步Callable
要想支持异步场景下使用缓存,则创建的时候必须要创建一个异步缓存类型,可以通过buildAsync()方法来构建一个AsyncCache类型缓存对象,进而可以在异步场景下进行使用。
看下面这段代码:
public static void main(String[] args) {
AsyncCache<String, User> asyncCache = Caffeine.newBuilder().buildAsyn();
CompletableFuture<User> userCompletableFuture = asyncCache.get("123", s -> userDao.getUser(s));
System.out.println(userCompletableFuture.join());
}上述代码中,get方法传入了Callable回源逻辑,然后会开始异步的加载处理操作,并返回了个CompletableFuture类型结果,最后如果需要获取其实际结果的时候,需要等待其异步执行完成然后获取到最终结果(通过上述代码中的join()方法等待并获取结果)。
我们可以比对下同步和异步两种方式下Callable逻辑执行线程情况。看下面的代码:
public static void main(String[] args) {
System.out.println("main thread:" + Thread.currentThread().getId());
// 同步方式
Cache<String, User> cache = Caffeine.newBuilder().build();
cache.get("123", s -> {
System.out.println("同步callable thread:" + Thread.currentThread().getId());
return userDao.getUser(s);
});
// 异步方式
AsyncCache<String, User> asyncCache = Caffeine.newBuilder().buildAsync();
asyncCache.get("123", s -> {
System.out.println("异步callable thread:" + Thread.currentThread().getId());
return userDao.getUser(s);
});
}执行结果如下:
main thread:1
同步callable thread:1
异步callable thread:15结果很明显的可以看出,同步处理逻辑中,回源操作直接占用的调用线程进行操作,而异步处理时则是单独线程负责回源处理、不会阻塞调用线程的执行 —— 这也是异步处理的优势所在。
看到这里,也许会有小伙伴有疑问,虽然是异步执行的回源操作,但是最后还是要在调用线程里面阻塞等待异步执行结果的完成,似乎没有看出异步有啥优势?
异步处理的魅力,在于当一个耗时操作执行的同时,主线程可以继续去处理其它的事情,然后其余事务处理完成后,直接去取异步执行的结果然后继续往后处理。如果主线程无需执行其余处理逻辑,完全是阻塞等待异步线程加载完成,这种情况确实没有必要使用异步处理。
想象一个生活中的场景:
周末休息的你出去逛街,去咖啡店点了一杯咖啡,然后服务员会给你一个订单小票。
当服务员在后台制作咖啡的时候,你并没有在店里等待,而是出门到隔壁甜品店又买了个面包。
当面包买好之后,你回到咖啡店,拿着订单小票去取咖啡。
取到咖啡后,你边喝咖啡边把面包吃了……嗝~
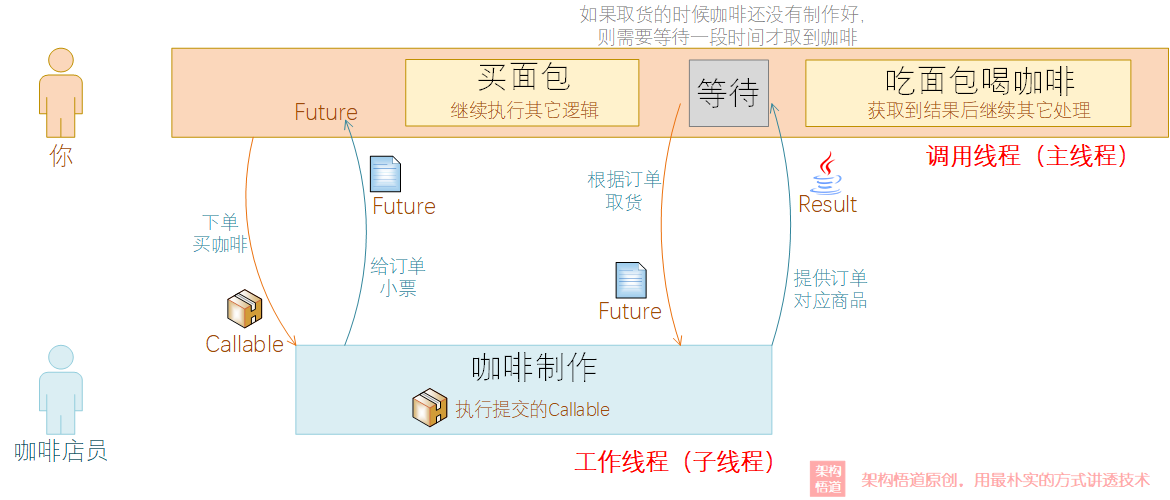
这种情况应该比较好理解了吧?如果是同步处理,你买咖啡的时候,需要在咖啡店一直等到咖啡做好然后才能再去甜品店买面包,这样耗时就比较长了。而采用异步处理的策略,你在等待咖啡制作的时候,继续去甜品店将面包买了,然后回来等待咖啡完成,这样整体的时间就缩短了。当然,如果你只想买个咖啡,也不需要买甜品面包,即你等待咖啡制作期间没有别的事情需要处理,那这时候你在不在咖啡店一直等到咖啡完成,都没有区别。
回到代码层面,下面代码演示了异步场景下AsyncCache的使用。
public boolean isDevUser(String userId) {
// 获取用户信息
CompletableFuture<User> userFuture = asyncCache.get(userId, s -> userDao.getUser(s));
// 获取公司研发体系部门列表
CompletableFuture<List<String>> devDeptFuture =
CompletableFuture.supplyAsync(() -> departmentDao.getDevDepartments());
// 等用户信息、研发部门列表都拉取完成后,判断用户是否属于研发体系
CompletableFuture<Boolean> combineResult =
userFuture.thenCombine(devDeptFuture,
(user, devDepts) -> devDepts.contains(user.getDepartmentId()));
// 等待执行完成,调用线程获取最终结果
return combineResult.join();
}在上述代码中,需要获取到用户详情与研发部门列表信息,然后判断用户对应的部门是否属于研发部门,从而判断员工是否为研发人员。整体采用异步编程的思路,并使用了Caffeine异步缓存的操作方式,实现了用户获取与研发部门列表获取这两个耗时操作并行的处理,提升整体处理效率。
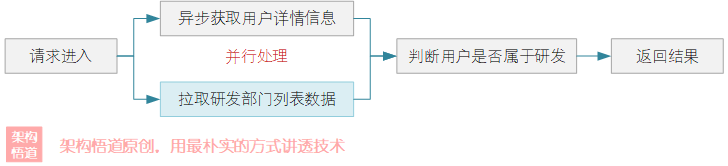
异步CacheLoader
异步处理的时候,Caffeine也支持直接在创建的时候指定CacheLoader对象,然后生成支持异步回源操作的AsyncLoadingCache缓存对象,然后在使用get方法获取结果的时候,也是返回的CompletableFuture异步封装类型,满足在异步编程场景下的使用。
public static void main(String[] args) {
try {
AsyncLoadingCache<String, User> asyncLoadingCache =
Caffeine.newBuilder().maximumSize(1000L).buildAsync(key -> userDao.getUser(key));
CompletableFuture<User> userCompletableFuture = asyncLoadingCache.get("123");
System.out.println(userCompletableFuture.join());
} catch (Exception e) {
e.printStackTrace();
}
}
异步AsyncCacheLoader
除了上述这种方式,在创建的时候给定一个用于回源处理的CacheLoader之外,Caffeine还有一个buildAsync的重载版本,允许传入一个同样是支持异步并行处理的AsyncCacheLoader对象。使用方式如下:
public static void main(String[] args) {
try {
AsyncLoadingCache<String, User> asyncLoadingCache =
Caffeine.newBuilder().maximumSize(1000L).buildAsync(
(key, executor) -> CompletableFuture.supplyAsync(() -> userDao.getUser(key), executor)
);
CompletableFuture<User> userCompletableFuture = asyncLoadingCache.get("123");
System.out.println(userCompletableFuture.join());
} catch (Exception e) {
e.printStackTrace();
}
}与上一章节中的代码比对可以发现,不管是使用CacheLoader还是AsyncCacheLoader对象,最终生成的缓存类型都是AsyncLoadingCache类型,使用的时候也并没有实质性的差异,两种方式的差异点仅在于传入buildAsync方法中的对象类型不同而已,使用的时候可以根据喜好自行选择。
进一步地,如果我们尝试将上面代码中的asyncLoadingCache缓存对象的具体类型打印出来,我们会发现其具体类型可能是:
com.github.benmanes.caffeine.cache.BoundedLocalCache.BoundedLocalAsyncLoadingCache而如果我们在构造缓存对象的时候没有限制其最大容量信息,其构建出来的缓存对象类型还可能会是下面这个:
com.github.benmanes.caffeine.cache.UnboundedLocalCache.UnboundedLocalAsyncLoadingCache与前面同步方式一样,我们也可以看下这两个具体的缓存类型对应的UML类图关系:
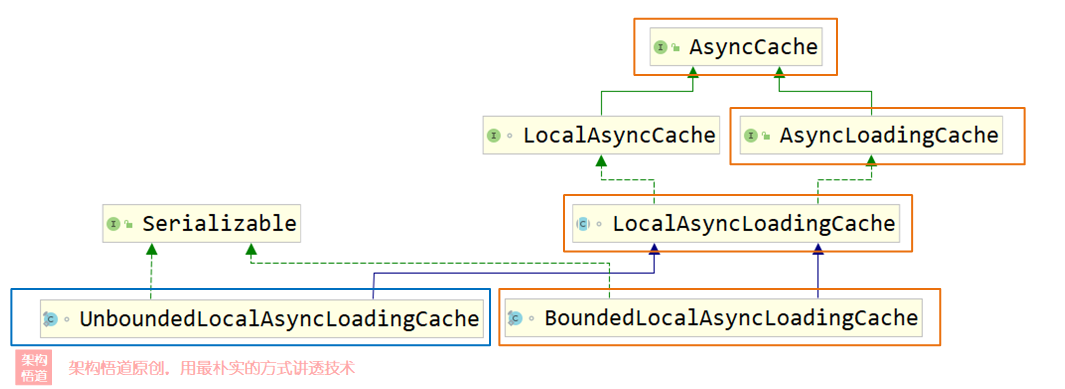
可以看出,异步缓存不同类型最终都实现了同一个AsyncCache顶层接口类,而AsyncLoadingCache作为继承自AsyncCache的子类,除具备了AsyncCache的所有接口外,还额外扩展了部分的接口,以支持未命中目标时自动使用指定的CacheLoader或者AysncCacheLoader对象去执行回源逻辑。
小结回顾
好啦,关于Caffeine Cache的同步、异步数据回源操作原理与使用方式的阐述,就介绍到这里了。不知道小伙伴们是否对Caffeine Cache的回源机制有了全新的认识了呢?而关于Caffeine Cache,你是否有自己的一些想法与见解呢?欢迎评论区一起交流下,期待和各位小伙伴们一起切磋、共同成长。
下一篇文章中,我们将深入讲解下Caffeine改良过的异步数据驱逐处理实现,以及Caffeine支持的多种不同的数据淘汰驱逐机制和对应的实际使用。如有兴趣,欢迎关注后续更新。
📣 补充说明1 :
本文属于《深入理解缓存原理与实战设计》系列专栏的内容之一。该专栏围绕缓存这个宏大命题进行展开阐述,全方位、系统性地深度剖析各种缓存实现策略与原理、以及缓存的各种用法、各种问题应对策略,并一起探讨下缓存设计的哲学。
如果有兴趣,也欢迎关注此专栏。
📣 补充说明2 :
- 关于本文中涉及的演示代码的完整示例,我已经整理并提交到github中,如果您有需要,可以自取:https://github.com/veezean/JavaBasicSkills
我是悟道,聊技术、又不仅仅聊技术~
如果觉得有用,请点赞 + 关注让我感受到您的支持。也可以关注下我的公众号【架构悟道】,获取更及时的更新。
期待与你一起探讨,一起成长为更好的自己。


 码字不易,感谢鼓励
码字不易,感谢鼓励
